Spreadsheets or Databases
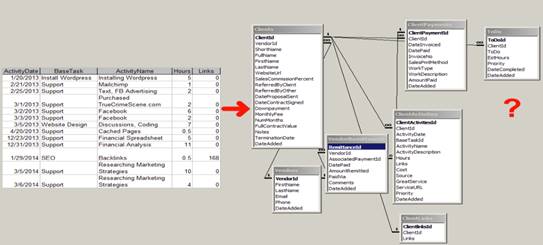
To database, or not, that is the question.
So, let’s say you are tasked to develop a test station
which will automatically take data from devices or products you have
manufactured. Development time for the physical station and software
takes, let us say, 4 weeks. Your lot of devices (or products) to be
tested is only a few dozen. The plan is to have this station
automatically measure and extract 15 key parameters needed for product
development. At this point you have all of your manager's attention.
Then, you go and tell them it is going to take another 2 months to get the
data into a database. At this point you'll probably hear, "just stuff
it into a spreadsheet". But is it really worth not developing the
database?
An errored entry might be seen and could be manually removed for the data
population in a spreadsheet. You could assume these extreme outliers
were typed in error. But what do you do when you are running
multi-variate experiments where you are changing 3 or 4 input parameters of
the device? These extreme outliers may not be so obvious and could
actually be real data. But how do you know without wasting additional
engineering hours manual checking the data.
A skilled typist, which I am certainly not, can enter data at a rate of
around 10,000 characters an hour. Large floating-point numbers would
probably be at a much slower rate. Let’s say, this most skilled typist
has an error rate of 0.1%. For this example, that would mean 10 errors
were introduced per hour, 80 errors per shift. Now, multiply that
times the number of people entering data. So even with an error rate
of 0.1% you would still be introducing significant damage to your data set.
You could try to bypass the manual data entry by using Optic Character
Recognition (OCR). Just print the page of test data, scan it, and
convert it so your spreadsheet can digest it. However, even this comes
with its own problems. I would like to say the technology is 100%, but
the reality is it is not. And any benefit to scanning in the data
would be lost because the data would still need to be massaged for entry
into your spreadsheet.
In addition to the problems of the speed, quality, and the costs related to
manual data entry, you also lose the ability to cross-correlate data.
Yes, some spreadsheets do have sophisticated querying tools, but these
spreadsheets tend to become single use projects. Use them and lose
them, lost in the cloud or network drive forever. How many times have you had
to scan your network looking for data from a spreadsheet you generated 3
years ago, and then cut & paste it together with your current project
spreadsheet, and then having to convert the data to common units. Too
much wasted time, too much opportunity to introduce error.
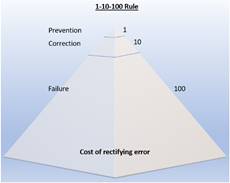 Years
ago, I read an article which applied the 1-10-100 rule to manual data entry.
A company will spend $1 to verify the data it has entered, $10 correcting
the mistakes, and $100 to correct errors caused when these errors slip
through. Just one error strategically located in your spreadsheet
could set a project off in the wrong direction costing time, money, and
manpower. So, to database we go, but where do you begin? You
begin by organizing your thoughts, thinking ahead, and planning for future
expansion.
Years
ago, I read an article which applied the 1-10-100 rule to manual data entry.
A company will spend $1 to verify the data it has entered, $10 correcting
the mistakes, and $100 to correct errors caused when these errors slip
through. Just one error strategically located in your spreadsheet
could set a project off in the wrong direction costing time, money, and
manpower. So, to database we go, but where do you begin? You
begin by organizing your thoughts, thinking ahead, and planning for future
expansion.
They'll be the temptation to just deal with the data from the project at
hand. This would give you the ability to query parameters (data) which
are important to you. But what if you wanted / needed to
cross-correlate data from a different lot? You would need to query
your database and then, hand manipulate the data so it could be entered into
another database or spreadsheet. And with data manipulation come the
potential for data corruption and error.
This is where the 'organizing of your thoughts' comes into play. You'd
want to start small but develop something that could be expanded and grown
as the need arises. For this, I would suggest starting with a flat
database design. This is basically a one-page (table) database.
They are easy to setup but tend to get big fast. However, according to
Moore’s Law, memory sizes double every 18 months. No need to worry
about it any time soon. Starting with a flat database allows you to
start populating the database as the database itself is developed. The
neat thing about databases is the data can be reconfigured at any time.
No efforts are lost. As the need grows you can then grow your
database. You may find your engineering test database may become
useful to other departments in the company. With that, these other
department may want to add table of their own. At this point, the
database could be converted from a flat style database to a relational
database. In short, a relational database is a series of different
tables that interconnect using common fields from each table. And this
is where the 'planning for future expansion' comes in.
One of the big problems with databases, especially engineering databases, is
'definition collision'. This is where similar field types are defined
in different ways. An example of this would be a field for voltage
defined as 'double float', and another voltage defined as a 'text' field.
Both work but the data would need to be manipulated before it could be used
in a correlation. So, what field types do you use and what units to
make the data fields? Should the data be stored as ‘100ma’, ‘0.001A’,
‘1’ in a field defined as mA??? Should it be an integer, float,
double, text or whatever??? Should the units be pre-embedded into the
number and just leave to the user to figure it out? This is where most
database projects fail. And having done this before I will say, ‘there
is nothing more annoying than seeing units pop up in reports like KuA
(kilo-micro A) or muA (milli-micro A). Or trying to plot data that was
defined as text with embedded alphanumeric characters in it. Look, a
Number is a Number, and a Label is a Label.
Getting back to Moore’s Law,
memory is cheap, with size doubles every 18 months. Unless your
database is being used for at the New York Stock Exchange I wouldn’t worry
about data size. Let Information Technologies (IT) worry about of
that. So, to keep it simple, I just defined labels as 'short text',
indexes as 'long integers', date & time as 'date/time', and floating-point
numbers as 'double floats'. With that said, I never embed the units in
the number. A value like 100uA is entered into the field as 0.000001,
and NOT 1.0 leaving you to assume the field is in uA. Computer are
good with large numbers, let it do the work. As shown in the example
just below, I sometimes put a secondary label field to describe the units in
the data field (ex. Test_I2_Units).
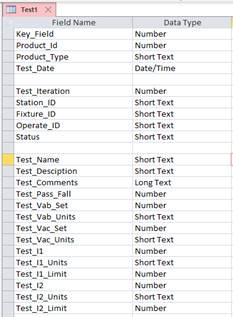 To
the left is a simple test database example for a flat style database.
The Key_Field is a unique long integer number, maybe made up of other data
fields which identifies the data set. They're not really necessary,
but it will make it easier to cross-correlate data from other tables as they
become available. I’ll usually do something like Key_Field =
Product_ID (8 or more digits) + Test_ID (4 digits) + Test_Instance (2
digits).
To
the left is a simple test database example for a flat style database.
The Key_Field is a unique long integer number, maybe made up of other data
fields which identifies the data set. They're not really necessary,
but it will make it easier to cross-correlate data from other tables as they
become available. I’ll usually do something like Key_Field =
Product_ID (8 or more digits) + Test_ID (4 digits) + Test_Instance (2
digits).
When entering data for the test station's grphical user interface (GUI) I
disallow users to directly enter data into the database fields. It is
a lot easier to force convention than to go back and post-process data to
correct it. So, generate a GUI which uses drop-down menus with
predefined selections for the operators to select. You’d be surprised
how many derivatives there are for a label like 'Preamp_1234' (pre-amp1234,
Pre-Amp 1234, pre_amp_1234, Preamp 1234, PA1234, etc.). You get the
idea. My preference would be to barcode or Q code the device under test,
the test station, and operator ID tag. A bar code scanner and tags
takes all the guess work out of it.
On last tip in closing. The Holy Grail for engineering test stations
would be for all your stations to be directly tied to the database.
Been there, big mistake. For starters, what happens
when IT takes down the database for maintenance, or repair. I can tell
you what happens, your production floor grinds to a halt and your boss
starts throwing darts at your picture. The same goes for lost
communications connections, server errors, data corruption, and station
errors. Business stops until these problems are corrected. So,
what is the work around? The solution I came up with was to have all
of the stations dump their data directly to a directory on the network.
A parsing program would then check this directory for files every 5 or 10
minutes and parse them into the database. The parser program could be
written so that it could distinguish between several different types of test
station files and parse the data into the correct field. This method
will insulate your test stations from the server and network crashes.
As systems come back online the parser continues where it left off and
parses the files into the database.
I hope this was helpful. Good Luck.